
Hvordan bruges det
1. Sådan opretter du et korpus (datasæt)
Dette værktøj vil analysere et korpus (et datasæt) af tekstdokumenter. Hvert dokument er simpelthen et stykke tekst, som du har fundet på nettet (eller andre steder). Det kan være så kort som en sætning eller så langt som en avisartikel. Men det skal være ren tekst (ingen billeder eller andre medier).
Lad os først se, hvordan det fungerer, og så vil vi se, hvor man finder dokumenter, og hvordan man udvælger dem.
Sådan kommer du i gang
Klik på “Kom i gang” i menuen for at indlæse “Dokumenter”-siden.
Hvis du bare vil se værktøjet i aktion, indlæs et eksempel fra menuen nederst på skærmen.

Hvis du vil lave dit eget korpus, så klik på “Tilføj dokument” for at begynde at redigere dit første dokument.

Dette åbner en grænseflade til at redigere dit første dokument.
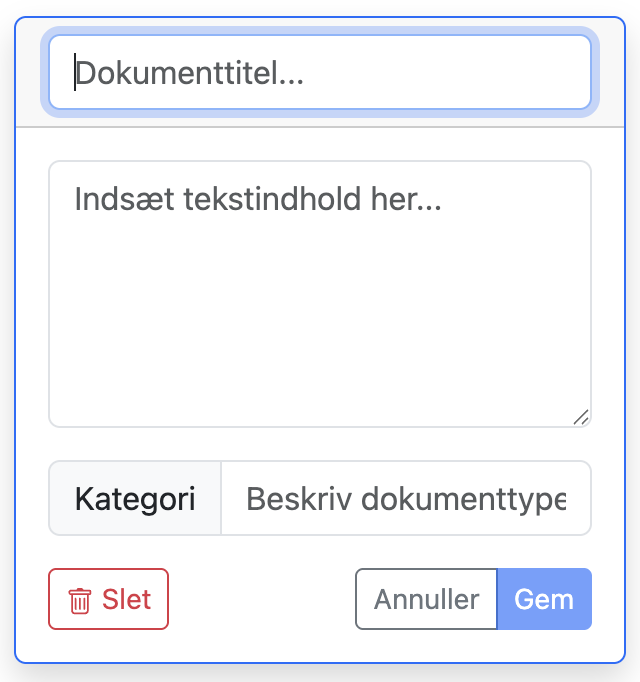
Et dokument består af tre dele:
- En titel
- Tekstindhold
- En kategori
Sådan udfylder du et dokument
Lad os antage, at du har en informationskilde, som en Wikipedia-side, til at bruge som dokument.
- Først skal du give en titel. Du kan opfinde den eller genbruge din kildes titel (hvis den har en). Det er bare en måde at identificere dit dokument nemt på. Skriv den i det øverste felt i grænsefladen.
- For det andet skal du kopiere og indsætte det tekstuelle indhold fra din kilde i det midterste felt i grænsefladen.
- For det tredje skal du skrive en kategori i det nederste felt. Vær konsistent i din stavning, ellers vil hver forskellige stavning tælle som en anderledes kategori. Vi forklarer, hvordan man beslutter kategorier længere nede.
Når du har udfyldt alle tre dele, kan du gemme dit dokument ved at klikke på “Gem”-knappen. Bemærk, at du ikke kan gemme dit dokument, hvis det ikke er fuldstændigt.
Sådan håndterer du datasættet
Du kan oprette så mange dokumenter, som du vil.
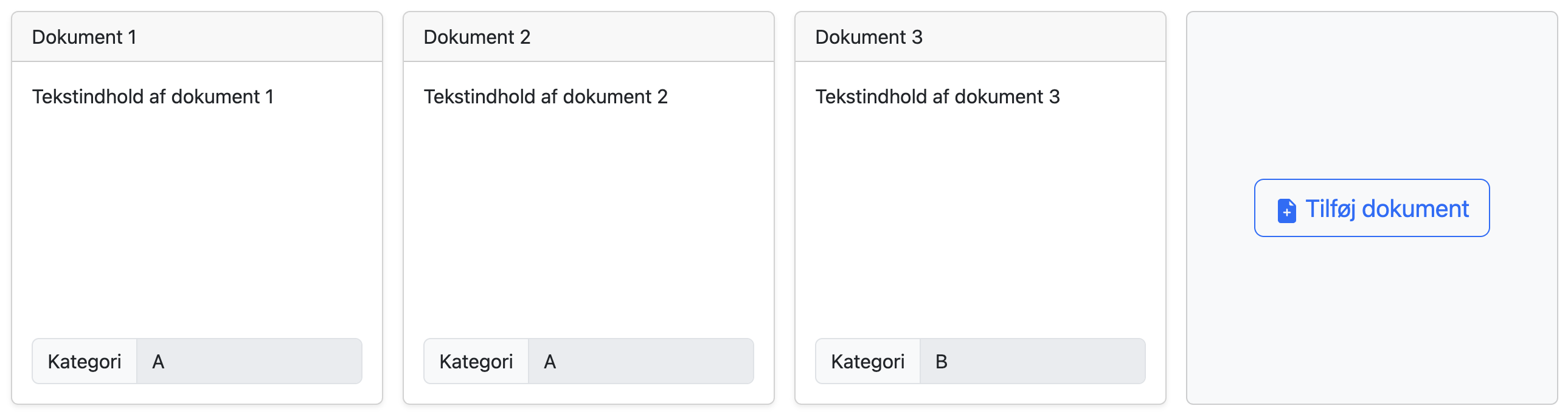
Vi mener, du har brug for mindst 10 dokumenter, men 20 er et bedre antal. Du kunne gå op til 50 eller flere, hvis din computer er kraftig nok (det vil tage længere tid at beregne).
Klik på et gemt dokument for at gå ind i redigeringstilstand igen. Du kan ændre det eller endda slette det. Husk at gemme (eller annullere) dine ændringer.
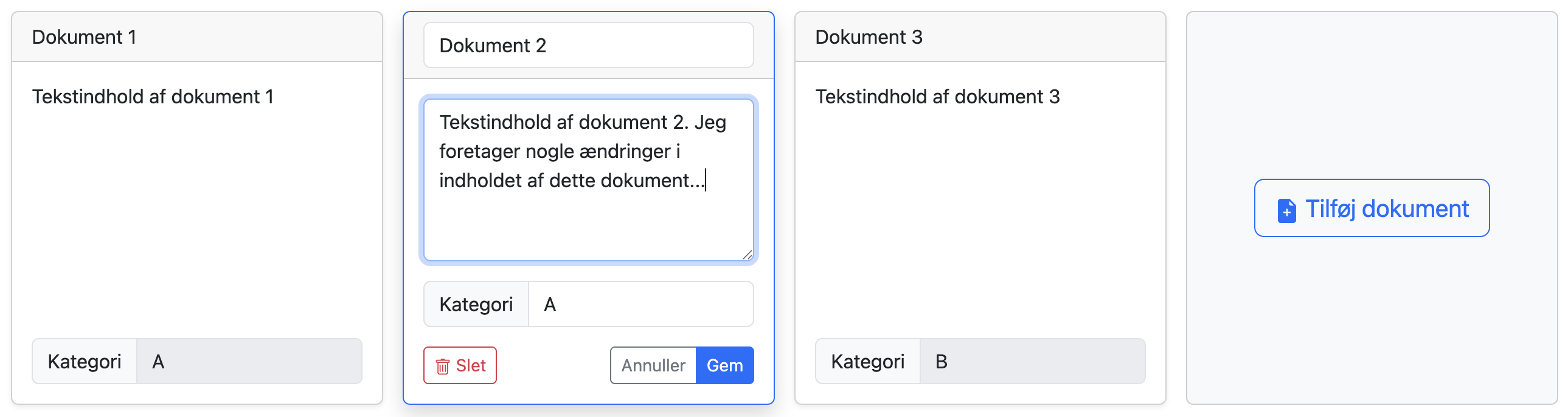
Du kan gemme dit datasæt ved at klikke på “Gem (CSV)“-knappen. Du vil kunne uploade det senere eller dele det med andre mennesker.

Når dit korpus er klar, skal du klikke på en af de tre tilgængelige algoritmer lige under dit sæt dokumenter. De gør forskellige ting. Du kan prøve dem alle. Du vil kunne komme tilbage til dine dokumenter og redigere dem, hvis du vil.

Hvor finder man dokumenter, og hvordan beslutter man kategorier?
Først og fremmest kan du bare prøve værktøjet og eksperimentere med det for at forstå, hvorfor kategorier betyder noget. Tøv ikke med at eksperimentere.
Det sagt, vil du opnå de bedste resultater under tre betingelser:
- Find dokumenter, der naturligt adskiller sig i to dele, som vand og olie.
- Vælg kategorier, der afspejler disse to dele.
- Det bør ikke være helt åbenlyst, at de to grupper er godt adskilt.
Hvis du tilføjer to grupper dokumenter, der er helt forskellige, for eksempel artikler om ost og artikler om sejlsport, vil de adskille sig, men det er ikke interessant, fordi vi ved med sikkerhed, at de vil gøre det. Måske ville det være interessant, hvis de ikke adskilte sig.
De gode dokumenter og kategorier bør altid være lidt overraskende. Hvis du tilføjer to grupper dokumenter, hvor det er svært at vide, om de vil være ens eller ej, så er det interessant. Det giver ny information, fordi vi ikke vidste det. Du finder eksempler nedenfor.
Dokumenterne og kategorierne hænger sammen. Vælg dem for at lave en interessant sammenligning. Tænk på dem som en måde at stille spørgsmål som: “Synes du, at dokumenter A og dokumenter B er ens eller forskellige?” Og selvfølgelig er det spørgsmål interessant, hvis det ikke har et åbenlyst svar. Algoritmerne vil give dig mulighed for at finde og besvare det spørgsmål, du stiller.
Du kunne sammenligne, hvordan vi taler om to lignende ting. For eksempel kunne du sammenligne, hvordan vi taler om to religioner, eller mænd og kvinder, eller to nationaliteter osv. Det kunne være en måde at se på diskrimination. For eksempel kunne du sammenligne Wikipedia-artikler om mandlige popartister med Wikipedia-artikler om kvindelige popartister. Dette ville stille spørgsmålet: “Er Wikipedia-artikler om mandlige og kvindelige popartister forskellige eller ens?” Svaret er ikke åbenlyst, fordi på den ene side er de alle popartister, men på den anden side er de mænd og kvinder. Så det er noget interessant at se på.
Du kunne også sammenligne, hvordan to forskellige medier skriver om den samme ting. Du kunne sammenligne, hvordan venstrefløjsaviser og højrefløjsaviser skriver om det samme emne, for eksempel immigration, Den Europæiske Union eller atomenergi. Eller du kunne sammenligne, hvordan samme emne diskuteres på sociale medier (Reddit, Facebook…) versus på mainstream medier (aviser, tv-kanaler…). Eller du kunne sammenligne lokalpresse og nationalpresse, eller lokalpressen i en region og i en anden region osv.
Der er endnu andre måder at lave interessante sammenligninger på, som gamle artikler versus nye artikler (f.eks. før og efter Covid), videnskab versus populærkultur osv. Vær kreativ!
Det vigtige er at vælge dokumenter, der har den forskel, du sigter mod at sammenligne, men ingen anden forskel. Hvis du sammenligner dokumenter fra to medier, behold det samme emne; omvendt, hvis du sammenligner to emner, vælg dokumenter fra samme medie eller lignende.
I dette værktøj kan et dokument være enhver tekst. Vær ikke bange for at kopiere og indsætte tekster, der ikke ligner traditionelle dokumenter, for eksempel diskussioner på sociale medier. Ikke hvert dokument behøver at se seriøst og officielt ud. Det afhænger af, hvad du vil sammenligne. Hvad normale mennesker siger over internettet, tæller også som information, der er værd at analysere.
Du finder dokumenter på mange offentlige hjemmesider: Wikipedia, Internet Movie Database, Fandom…
Du kan også bruge sociale medier som Reddit, YouTube (se på kommentarerne) osv.
Og via biblioteker kan du også få adgang til avisartikler fra mange medier. Disse er normalt bag en betalingsmur, men biblioteker giver ofte særlig gratis adgang til dem. Og nogle gange kan du søge i dem gratis, for eksempel BBC.
2. Sådan bruges: Tæl ordene
Denne algoritme tæller simpelthen i hvor mange dokumenter et givet ord er nævnt. Bemærk, at det ikke betyder noget, om ordet optræder en gang eller flere gange i samme dokument.
Skriv hvilket som helst ord i søgefeltet (og tryk Enter) for at starte optællingen.

Som standard vil dette ikke tælle det nøjagtige ord, men ethvert ord, der indeholder det. For eksempel vil “tog” også tælle “toge” og “togene”. Hvis du ikke vil det, marker indstillingen “Præcist ord”.

Alternativt kan du klikke på et af topordene for at søge efter det. Disse er defineret som de 25 ord, der optræder i det største antal dokumenter, stopord til side. Tallet i parentes angiver, i hvor mange dokumenter de optræder.

Bemærk: du kan finde andre gode ord at analysere i “Samord-netværk”.
Ordtællingsresultater
Din søgning vil vise dig resultatet af at tælle, hvor mange dokumenter der indeholder dit ord på to måder.
Først et søjlediagram, der viser procentdelen af dokumenter, der nævner din forespørgsel for hver kategori. Jo større søjlen er for hver kategori, jo større andel af dokumenter i den kategori nævner det ord, du søgte efter.

For det andet detaljer om, hvor ordet er nævnt i hvert dokument (hvis det er det).
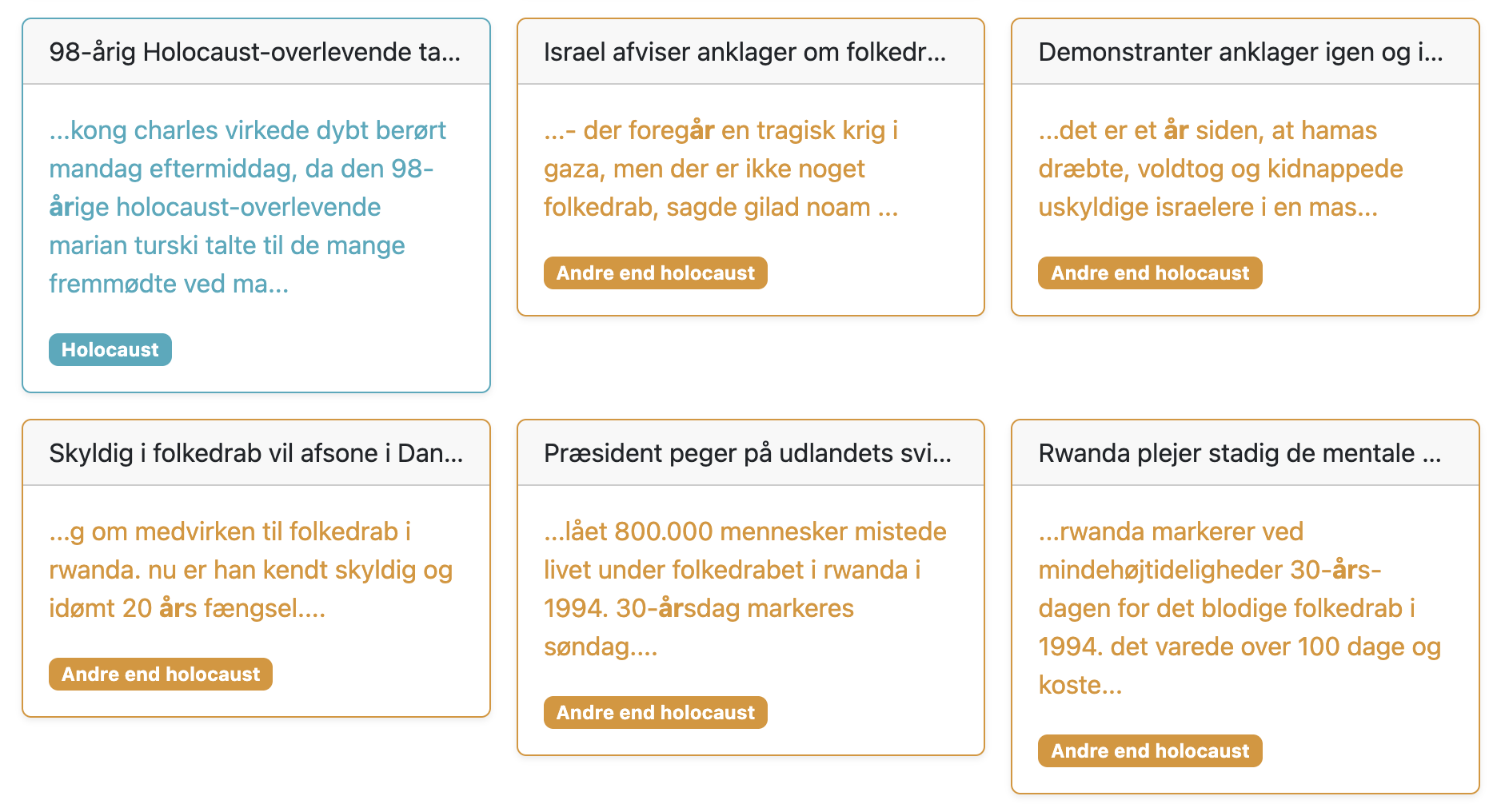
Brug disse detaljer til at verificere, at din forespørgsel fungerer som tilsigtet.
Prøv at finde ord, der kun matcher en kategori
De interessante ord er dem, der kun optræder i en af disse kategorier og ikke den anden. Disse ord karakteriserer en specifik kategori.
Her er et eksempel med datasættet af avisartikler om folkedrab, hvoraf nogle handler om Holocaust, og andre ikke gør.
Ordet “Holocaust” er næsten kun til stede i artiklerne om det…

…mens ordet “Rwanda” kun er til stede i artiklerne, der ikke handler om Holocaust (dog ikke i dem alle).
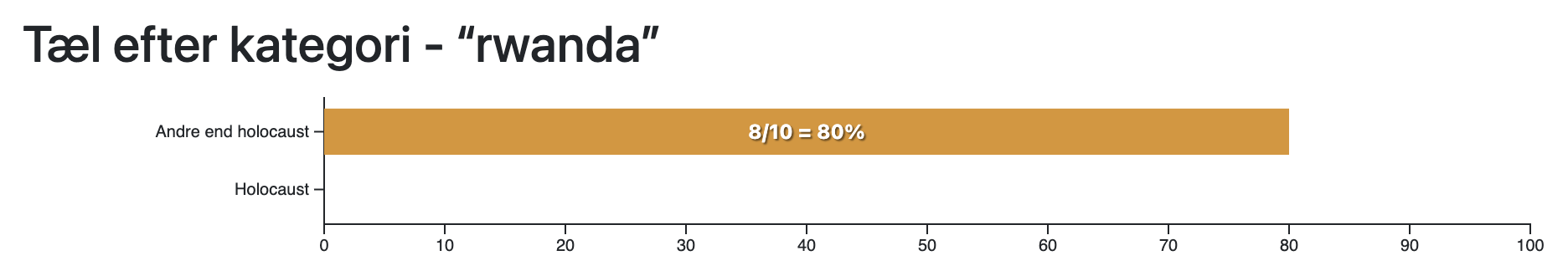
Dette eksempel viser dig, hvad det betyder for et ord at være karakteristisk for en enkelt kategori. For at finde interessante ord skal du bruge den næste algoritme, “Samordnetværk”, og se efter ord, der er farvet stærkt som en specifik kategori.
3. Sådan bruges: Samordnetværk
Denne algoritme laver et netværk af ord forbundet, når de optræder i samme dokumenter. Lad os se på det resulterende netværk, før vi vender tilbage til indstillingerne.
Hvis du har to meget forskellige slags dokumenter, vil netværket have to adskilte dele. I eksemplet nedenfor har du ordene fra BBC-nyhedsartikler om “fishing” (fiskeri, i blåt) og om “trains” (tog, i gult). Da fiskeri og tog ikke har noget til fælles, adskiller netværket sig ganske godt.
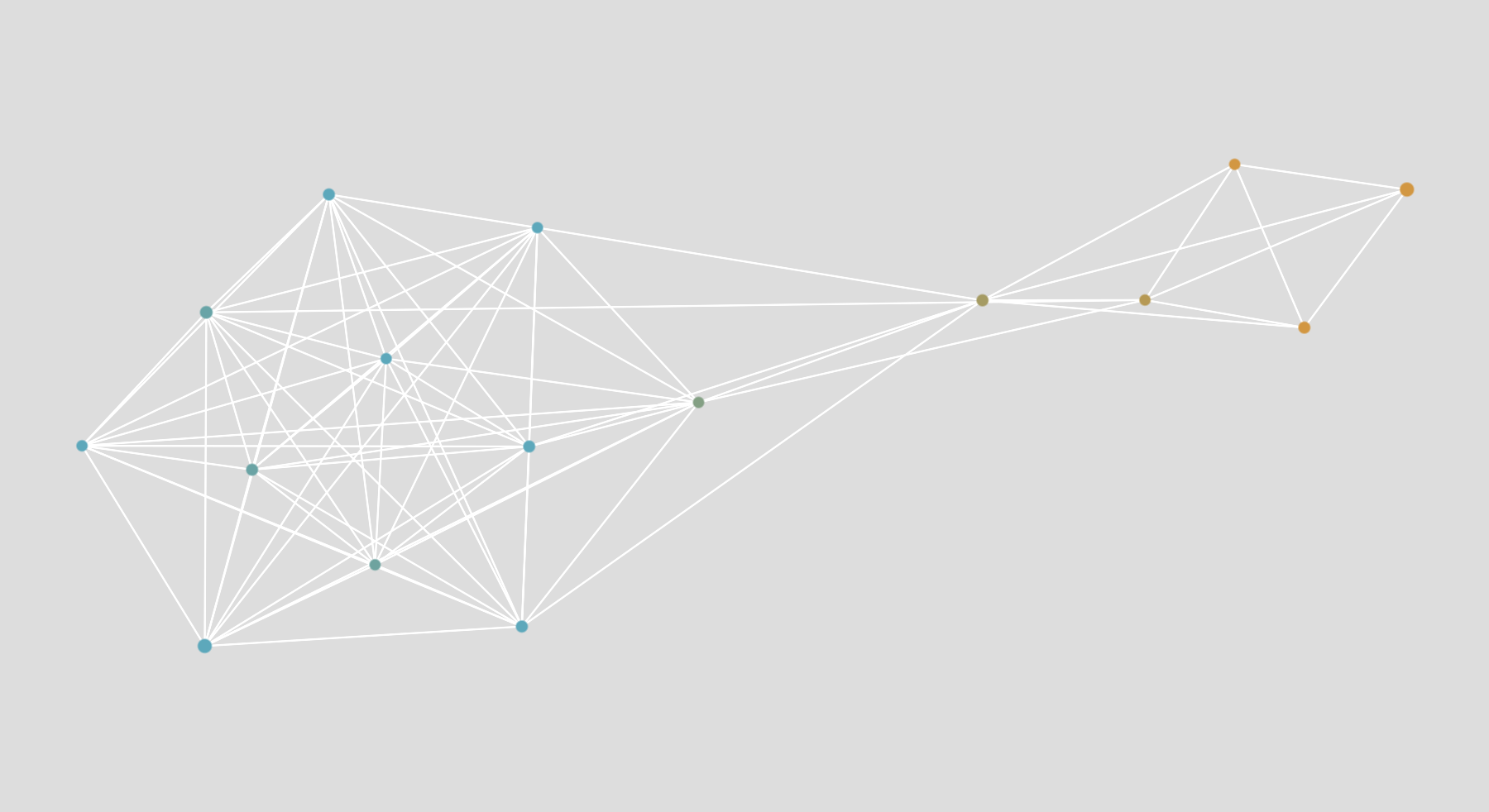
Bemærk: der er et ord, der forbinder den blå del med den gule del. Vi kalder det en “bro”. Det er en af de sjældne ting, de to slags dokumenter har til fælles. I dette tilfælde er det ordet “future” (fremtid).
Hvis dine dokumenter er relativt ens, vil netværket ikke se ud som om, det har adskilte dele. I eksemplet nedenfor har du ordene fra Wikipedia-artikler om mandlige og kvindelige popartister. Artiklerne er meget ens, og de fleste af ordene er de samme (“sang”, “music”…).
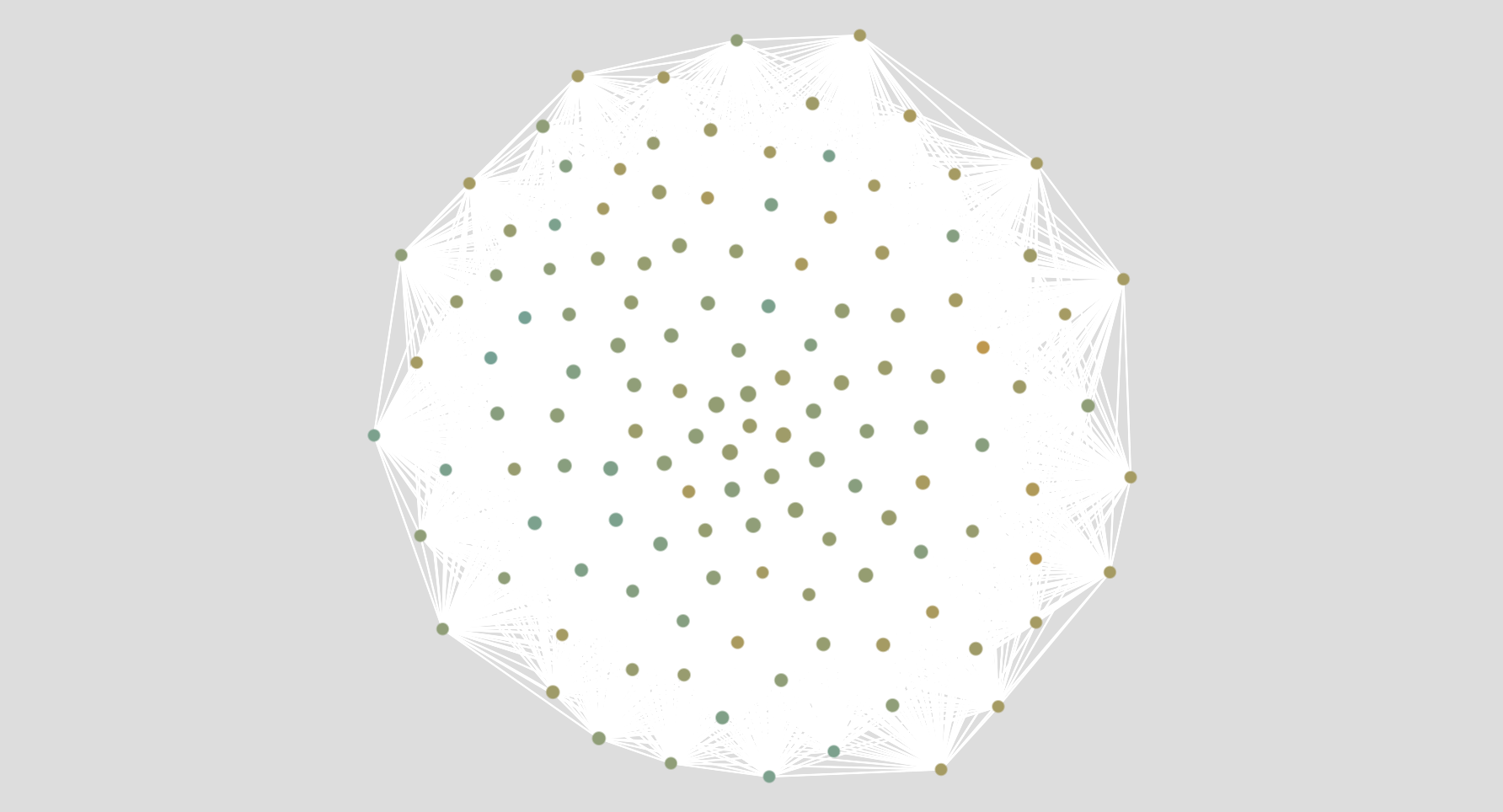
Hvis dine dokumenter er meget ens, og det ser ud som om, dine kategorier ikke adskiller sig godt, så prøv også den tredje algoritme “semantisk kort”, da den er endnu bedre til at finde forskelle. Dog visualiserer det semantiske kort dokumenter, mens dette netværk visualiserer ord.
Sådan bruges netværksindstillinger
Denne algoritme tæller også bare ordene, undtagen på en mere fancy måde end “tæl ordene”-algoritmen. Nogle gange er der forskellige måder at tælle på. Det er derfor, der er indstillinger: du kunne beslutte at tælle på en måde eller en anden. Du kan bare prøve forskellige indstillinger og se på resultaterne for at udforske algoritmen!
Indstillinger om tælling af ordforekomster
Det første trin handler simpelthen om at tælle ordene, i det væsentlige på samme måde som den første algoritme.

Skal titlen analyseres som del af teksten eller ej? Hvis du har opfundet titlen på dine dokumenter, så bør du formentlig ikke bruge den som del af teksten. Men hvis titlen faktisk var fra dokumentet, for eksempel med avisartikler, så er det en god ide at inkludere den.

Hvordan tæller man ordene? Vi har to muligheder.
- Tæl dem en gang pr. dokument, uanset hvor mange gange de optræder i det dokument.
- Tæl hvor mange gange de optræder i alt, inklusive når de optræder flere gange i samme dokument.
Vi tror, at den første mulighed fungerer bedre, men du kan prøve den anden. Det er interessant at se på den effekt, det producerer.
Med den første mulighed er den højeste score antallet af dokumenter i dit datasæt.
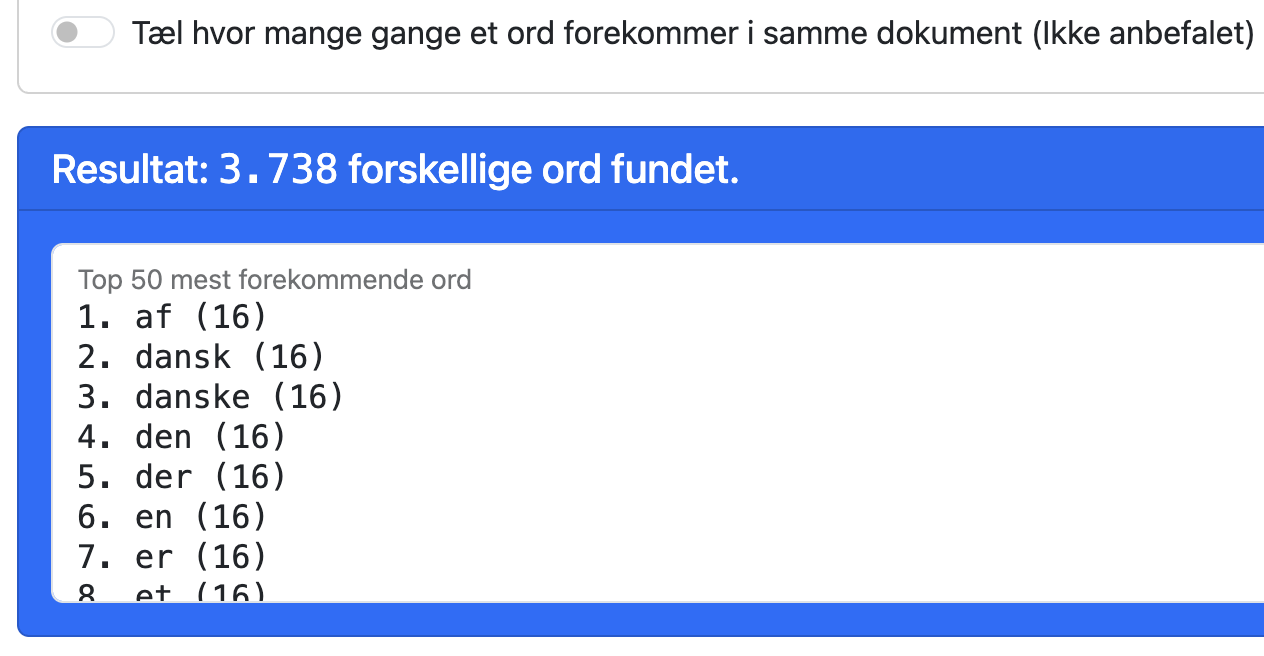
Med den anden mulighed er den højeste score meget højere, da nogle ord optræder mange gange i samme dokument.
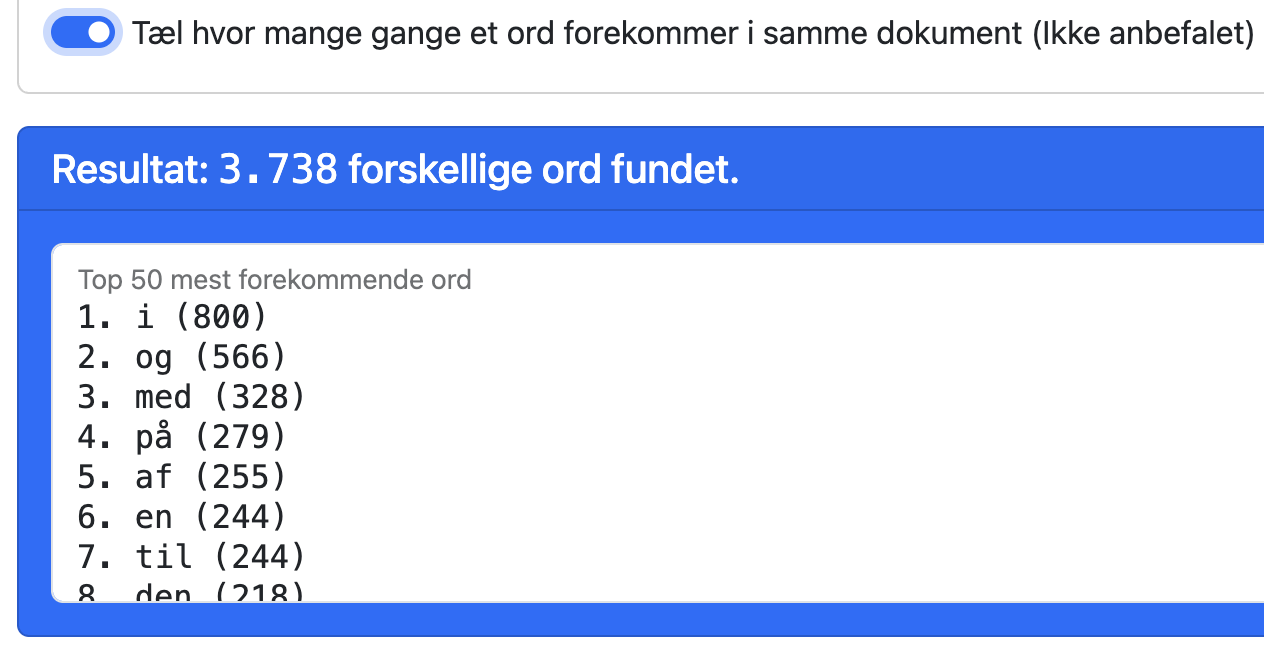
Som du kan se ved at sammenligne resultaterne, er ordene med den højeste score ikke de samme.
Indstillinger om fjernelse af unødvendige ord
Vi kalder “stopord” de ord i et sprog, som vi ikke finder interessante. Det er de værktøjsord, vi bruger til at få sætninger til at fungere, men som ikke bærer meget betydning, fordi de er overalt hele tiden. For eksempel “den”, “af” eller “og”.

Stopordene er ikke de samme på forskellige sprog. Dette værktøj har en stopordsliste for hvert sprog, det understøtter. Brug listen svarende til sproget i dine dokumenter.
Ordene med den højeste optælling har tendens til at være stopord, som du kan se ovenfor. Derfor vil vi fjerne dem. Når stopord er fjernet, er topordene mere interessante:

Ud over det vil vi også fjerne de ord, der ikke optræder ofte nok.

Brug den indstilling til at gøre dit netværk større eller mindre, hvilket afhænger af, hvor mange dokumenter du har, og hvor lange de er.
På den ene side behøver vi ikke, at netværket er for stort (langsommere at beregne, vanskeligere at læse). Men på den anden side, hvis du beholder ord, der optræder sjældnere, vil netværket være mindre interessant (fordi adskillelsesmønstret vil være svagere). Prøv at finde den bedste indstilling!
Samforekomster
Hver gang to givne ord optræder sammen i et dokument, siger vi, at de “samforekommer”. Derfor tæller “samforekomst”-scoren, hvor stærkt to ord er forbundet i datasættet.

Der er ingen indstillinger, da denne beregning er ligetil. Men det er interessant at se, hvilke par der samforekommer mest. Disse par vil blive til netværkets links.
Indstillinger om visning af netværket
Netværksvisualiseringen bruger en layoutalgoritme til at placere ordene i billedet, så de er tæt på hinanden, når de er forbundet (det vil sige, når de samforekommer). Målet er at gøre det synligt, når der er to eller flere grupper af ord (klynger), der matcher kategorierne. To indstillinger bruges til at forbedre resultatet, men du kan deaktivere dem, hvis du vil.
Den første forbedring er at normalisere samforekomstscorerne ved at bruge en metrik kendt som pointwise mutual information. Kort sagt hjælper det ved at tage højde for, at nogle af ordene nævnes oftere, hvilket gør dem mere tilbøjelige til at samforekomme. På et praktisk niveau gør det netværket mere læseligt.

Den anden forbedring er at fjerne de afkoblede ord. Disse er sjældne, men det kan nogle gange ske. De er distraherende og ikke særlig interessante, da de ikke er forbundet til andre ord, så vi kan bare fjerne dem.

Sådan læser du samordnetværket
Hver prik er et ord, farvet efter kategorier. Hver prik har en farveblanding svarende til kategorierne af de dokumenter, hvor det nævnes mest.
Hver hvid linje er en samforekomstrelation mellem de to forbundne ord.
To prikker (ord), der er forbundet (samforekommer), har tendens til at blive placeret tættere gennem effekten af layoutalgoritmen Force Atlas 2. Som resultat indikerer adskilte visuelle grupper, selvom de ikke er fuldstændigt afkoblede, emner (et emne værende en gruppe af ord, der har tendens til at blive nævnt sammen).
Bemærk, at layoutalgoritmen er “ikke-deterministisk”: resultatet varierer fra gang til gang, fordi det kræver en randomiseret initialisering. Dog, som du kan se, hvis du prøver, er klyngerne (emnerne) altid de samme. De kan være roteret, vendt eller lidt ændret, men de vil altid være de samme, have samme størrelse osv.
Du kan flytte netværksvisningen ved at trække med markøren eller fingeren på en touchskærm og zoome ind og ud med scrollhjulet, knib zoom eller tilsvarende understøttet af din enhed. Brug det til at udforske netværket og finde interessante ord.
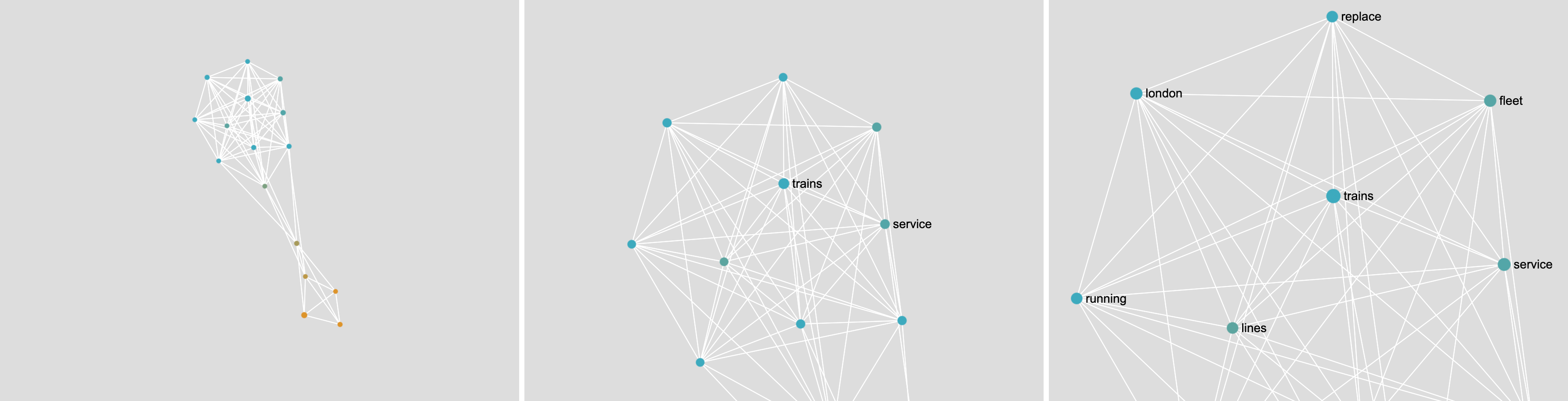
4. Sådan bruges: Semantisk kort
Denne algoritme er helt automatisk og kræver ingen indstillinger. Den fungerer i to dele.
Den første del består af at bruge en “tekstindlejringsmodel”, og mere præcist all-MiniLM-L6-v2, som er flersproget (den “taler” de fleste sprog). Den transformerer enhver tekst til en semantisk repræsentation. Vi vil ikke forklare, hvordan det fungerer, men snarere hvad det gør.
Denne model bruger AI til at transformere enhver tekst til en række tal. I matematik siger vi, at den bliver “indlejret” i en “vektor”. Hver vektor er meget lang (hundredvis af dimensioner) og koder betydningen af den tekst. På et praktisk niveau har disse vektorer en meget interessant egenskab: lignende tekster producerer lignende vektorer.
Afstanden mellem vektorer koder semantisk lighed:
- Helt forskellige dokumenter producerer meget fjerne vektorer
- Dokumenter om samme emne producerer ganske tætte vektorer
- Dokumenter, der betyder det samme, men skrevet anderledes, har meget tætte vektorer
- Næsten-identiske dokumenter producerer næsten-overlappende vektorer.
Vi bruger denne egenskab til at producere det semantiske kort.
Den anden del af algoritmen består af at visualisere vektorrummet som et kort. Dette kaldes “dimensionalitetsreduktion”, fordi vi reducerer de meget lange vektorer til to dimensioner. Med andre ord reducerer vi dem til punkter på et plan. For at gøre dette bruger vi en teknik kaldet UMAP. Du kan lære om det på denne side. Kort sagt producerer det et kort, der bevarer den vigtigste egenskab: afstand koder semantisk lighed.
Det resulterende semantiske kort kan læses således:
- Hver prik er et dokument fra dit datasæt
- Farven på dokumentet angiver dets kategori
- Prikker (dokumenter) er tæt på hinanden, når de har lignende indhold, og er langt fra hinanden, når de har forskelligt indhold.
Ligesom for samordnetværket er denne visualisering ikke-deterministisk. På grund af en tilfældig initialisering af algoritmen er resultatet lidt anderledes hver gang. Dog vil grupperne af prikker eller “klynger” altid være de samme. De vil simpelthen blive vendt eller roteret hver gang.
Sådan fortolker du det semantiske kort
Kig på det semantiske kort og stil dig selv to spørgsmål:
- Er der forskellige grupper af prikker (klynger)?
- Er der forskellige farvegrupper?
Disse to spørgsmål kan ved første blik se ens ud, men de er faktisk to forskellige og uafhængige spørgsmål.
Er der forskellige klynger?
Med “forskellige grupper” mener vi grupper af prikker, der befinder sig i forskellige dele af billedet. Vi kan også kalde dem “klynger”. Hver klynge består af prikker (dokumenter), der ligger tæt på hinanden, mens klyngerne selv er langt fra hinanden.
I eksemplet nedenfor har vi en enkelt klynge. Det betyder, at alle dokumenter har et lignende indhold.

I eksemplet nedenfor har vi to forskellige klynger. Det betyder, at der er to grupper af dokumenter med forskellige indhold, sandsynligvis to forskellige emner.

Bemærk at brugen af forskellige sprog i samme datasæt også kan producere forskellige klynger.
Klyngerne handler kun om tekstindholdet af dokumenterne, ikke om kategorien. Klyngerne identificeres ved kun at se på prikkernes placering. Klynger er uafhængige af farven. Placeringen tager ikke hensyn til dine kategorier. Dette punkt er meget vigtigt, som vi vil se.
Er der forskellige farvegrupper?
Det andet spørgsmål du skal stille er, om farverne er blandet eller grupperet sammen.
Hvis farverne er blandet, betyder det, at dine kategorier ikke fanger nogen semantisk forskel. Med andre ord er dokumenter af samme kategori ikke særligt ens. Det kunne se sådan ud:

Hvis farverne danner grupper, betyder det, at de fanger en semantisk lighed. Det kunne se sådan ud:

I eksemplet ovenfor er dokumenterne ikke meget forskellige, fordi de danner en enkelt klynge. Ikke desto mindre har klyngen to sider, som viser, at der er semantiske forskelle inden for klyngen. Kategorierne fanger stadig en lille semantisk forskel.
Meget vigtigt, at have klynger betyder ikke, at dine kategorier fanger deres semantiske forskel.
Faktisk er det muligt at have to klynger (i forhold til prikkernes placering) og alligevel have blandede farver. Det vil se sådan ud:

Det rigtige at gøre i dette eksempel er at forstå, hvad de to grupper er, og gøre kategorierne om i overensstemmelse hermed. På denne måde vil du kunne forklare, hvad der gør dokumenterne forskellige.
Når farver og klynger matcher, som kan se ud som eksemplet nedenfor, så fanger kategorierne de semantiske forskelle mellem dokumenterne.
